In plain English
Finds cheap things to do in Copenhagen for you. It automatically reads a stack of Danish deal sites, collects the discounts in one searchable place with a map, and pings you on Telegram when a good one appears.
End-to-end · Solo build
Deal Round
A Copenhagen deal aggregator that scrapes 8+ Danish deal sites, filters out junk, deduplicates listings, and presents them in a polished web app with search, map view, and geolocation.
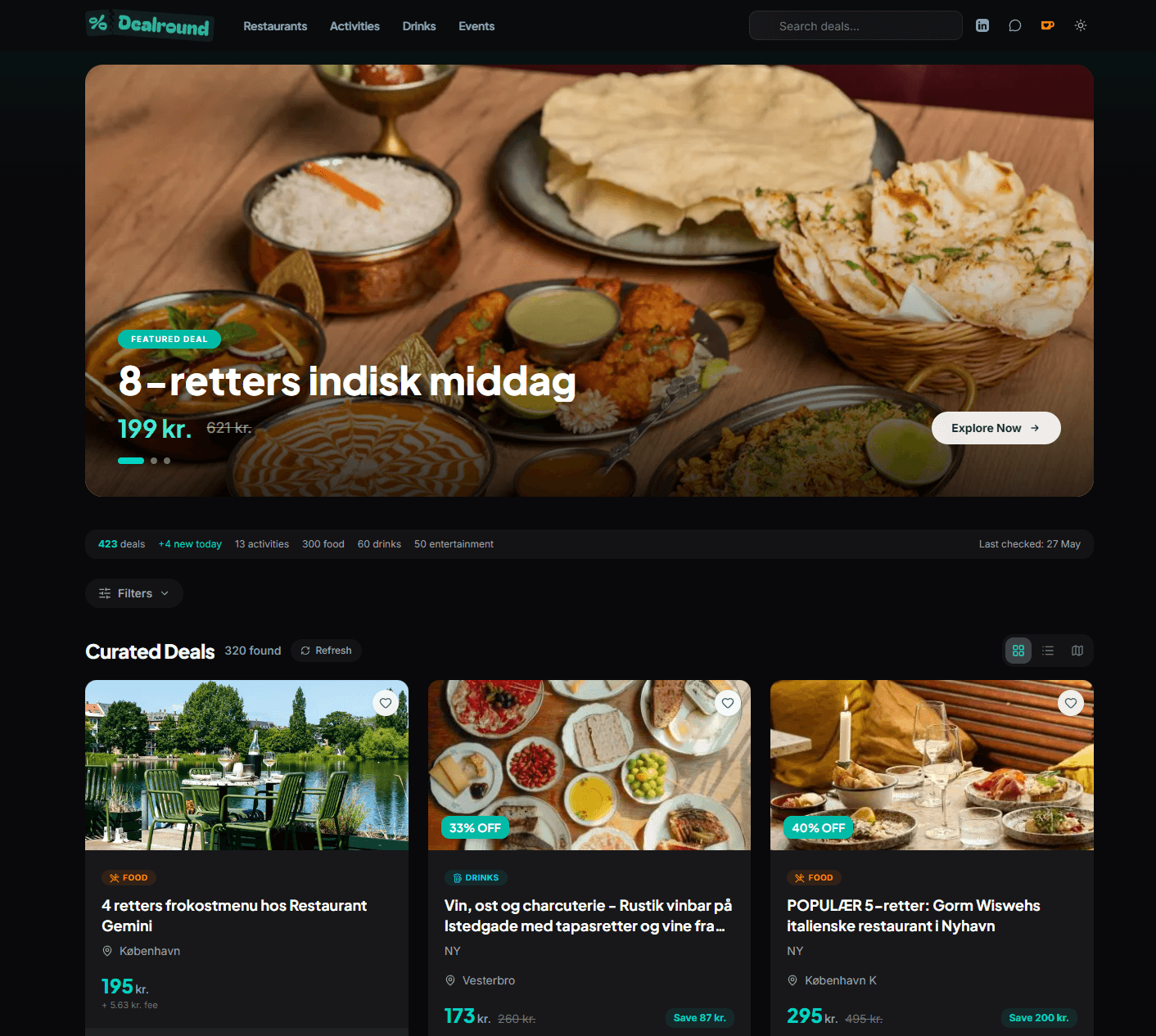
Try it
Find tonight's deal in Copenhagen
Free, no signup, works on phone or desktop.
By the numbers
Live since
Feb 2026
Running unattended
Visitors / 30d
42 organic
79% DK, then US + IT
Sources
8 sites
4× daily scrape
Stack cost
€5 / mo
Hetzner + Vercel
Why I built this
Living in Copenhagen, I kept missing good deals on activities, restaurants, and entertainment because they were scattered across different Danish deal sites. I wanted one place to see everything (filtered, deduplicated, and mapped) with Telegram alerts so I never miss a deal that matches my interests.
How it works
Scrape deals from 8+ Danish sites
A Python scraper runs four times daily (00, 06, 12, 18 CET) on a Hetzner VPS, pulling deals from Meyou.dk, Sweetdeal, All2day, Bownty, Madbillet, and more. Handles Danish compound words and bilingual keyword matching.
Filter, deduplicate, and classify
Aggressive quality filtering removes ~60% of raw scrapes: products, fake discounts, non-Copenhagen locations, and junk providers. Duplicate venues across sources keep only the lowest price. Food deals with drink keywords get auto-reclassified.
Browse, search, and filter in the web app
A Next.js frontend on Vercel shows deals in grid, list, or map view. Filter by category, price range, time added, and expiry. Sort by newest, cheapest, or highest discount. Use "Near Me" to find deals closest to your location.
Get notified via Telegram
New deals matching your interests are sent to a Telegram channel twice daily. SQLite deduplication ensures you only see new deals.
Key features
3 view modes
Grid cards, compact list, and interactive Leaflet map with marker clustering
4 categories
Activities, Food, Drinks, Entertainment, color-coded with smart filtering
Geolocation
"Near Me" button calculates distance to 30+ Copenhagen neighborhoods and Sjælland suburbs via Haversine
Advanced search
Full-text search, price ranges, time filters, sort by discount/price/date
Dark mode
Auto-detects system preference, instant toggle with no flash on load
Tech stack
Frontend
Vercel Analytics + Speed Insights for anonymous event tracking
Maps
CartoDB tiles (free, no API key), react-leaflet-cluster for marker grouping
Backend and Scraping
BeautifulSoup for HTML parsing, APScheduler for cron jobs
Infrastructure
Under the hood
I split the work in two: the website lives on a free host, and a small always-on machine quietly gathers deals around the clock. That keeps the whole thing running for about the price of a coffee per month.
The same restaurant often shows up on several sites at slightly different prices. I taught the app to recognise these matches and keep only the cheapest version, so you never scroll past the same deal twice.
Data sources
Scraped four times daily (00, 06, 12, 18 CET), typically yields 400-500 visible deals after filtering
Brand & creative
Visual identity, ads, and product photoshoot
Logo, social ad creative, and styled product photoshoot generated with Pomelli, Google's AI brand toolkit.

 Static ad
Static ad Photoshoot
PhotoshootInstall as PWA
Install Dealround like a native app
Four taps from your browser to a home-screen icon. No App Store, no install size, instant updates.
 1
1 2
2 3
3 4
4Common questions
Is it free?+
Yes, completely free. No account, no signup, no ads.
Is it only Copenhagen, or other cities too?+
Greater Copenhagen plus immediate Sjælland suburbs (Frederiksberg, Amager, Helsingør, Roskilde, Lyngby, Charlottenlund, Hellerup, Hvidovre, Brønshøj, Vanløse, Nordsjælland). The geocoding pipeline covers 30+ neighborhoods, so expanding to other Danish cities is non-trivial.
Are the deals verified?+
Filtered, not manually verified. About 60% of raw scrapes get rejected as junk (products, fake discounts, wrong locations). Always confirm on the original deal site before booking.
Why use this instead of going to Sweetdeal or Bownty directly?+
Everything in one place, deduplicated, mapped, and filterable by category, price, distance, or recency. Saves opening eight tabs.
Is anything tracked?+
Vercel Analytics tracks anonymous events (filter clicks, theme toggle, deal opens) for product decisions. No accounts, no personal data, no third-party trackers. Favorites live in your browser's localStorage and never leave the device.
Who maintains it?+
Solo side project by me, Auri. Spotted a broken deal or want to suggest a source? Ping me via the contact link in the footer.
What I learned
- ·The hardest part of a deal site is not collecting deals, it is throwing the bad ones away. Roughly 60% of what I gathered was junk, so ruthless filtering is what makes it actually useful.
- ·Most people landed on it from their phone, so I made the simple list view the default on small screens and saved the fancier map and grid for bigger ones.
- ·You can build a genuinely polished map and a clean experience using only free tools, no paid services required.
What's next
Honest roadmap. Things I know are gaps, in priority order.
Scraper-failure detection
Today, if a scraper returns zero items the run continues silently and I notice only when the deal count drops. Need a per-source health check + Telegram alert when any source returns nothing two runs in a row.
Per-source freshness indicator
The "Last checked" stat is global. Surfacing it per source would let users (and me) spot a dead scraper at a glance.
Custom domain for the backend
The Hetzner API is currently exposed on a bare IP, which makes CORS and HTTPS awkward. Moving it behind api.dealround.online with a proper cert is a one-evening fix that's been on the list.
Expand beyond Copenhagen
Aarhus and Odense are the obvious next cities, but the geocoding lookup table and neighborhood blocklist are CPH-tuned. Expansion is a real refactor, not just a config flip.